Designing a traditional classified ads e-commerce system, similar to Facebook Marketplace, presents challenges in server procurement, maintenance, and scalability to manage high traffic and growing business complexity. These issues result in elevated costs and reduced efficiency with business growth. To achieve cost optimization, enhance system performance, and ensure security, migrating workloads to AWS is a viable solution.
This article explores the strategy with a simple example, similar to Facebook Marketplace and Gumtree.
System Requirement Clarification
For simplicity, we focus on the following core requirements of the system:
Functional Requirements(FR):
- Sellers must be able to publish, edit, and delete products.
- Users must be able to search for products using keywords.
- The system must enable buyers to send inquiries and notify sellers via email.
Non-functional Requirements(NFR):
- The service needs to be highly available to ensure consistent and reliable access for users.
- The service needs to be highly scalable to effectively accommodate the growing number of users and interactions.
- The service needs to be highly secure, encompassing features such as data encryption in transit and at rest, along with robust user authentication and authorization mechanisms.
- The service needs to be highly extendable, supporting the integration of emerging features and technologies, such as machine learning for enhancing recommendation systems.
Design Consideration
- The system is read-heavy with an estimated read-write ratio of 100:1
- All product posts, including up to 9 photos each, require reliable and near real-time retrieval.
Capacity Estimation
The storage requirements are primarily determined by four factors: the number of posts, the volume of user data, storage needs for Elasticsearch indexing, and memory requirements for the distributed caching system.
- Assuming a total user base of 200 million, we have 1 million daily active users.
- Assuming a 100:1 read-write ratio, approximately 10,000 new posts are created daily.
- Assuming an average of 50 words per post and 5 bytes per word.
- Assuming each post contains an average of 5 photos, each photo utilizing 2MB of block storage for different compression levels.
- Assuming the business has operated at this scale for a continuous period of 5 years.
For simplicity, we’ll assume that the storage used before reaching the current scale is equivalent to one year’s storage at the current scale.
This estimation serves as a simplified representation of the core concept for illustrative purposes. In practice, more complex scenarios and requirements, such as logging and data for machine learning, need to be considered.
The storage required for posts will be
10000*365*(5+1)*50*5 + 10000*365*(5+1)*(2048*1024)*5 ≈ 209TBwhere daily new posts require around 97.66GB of storage.
User storage requirements:
- User ID (8 Bytes): This should be sufficient to support 200 million users and provides ample scalability.
- Username (32 bytes): A 32-byte username length should be sufficient for most cases, allowing for relatively long usernames.
- Email (64 bytes): A 64-byte email address length should be sufficient to support various email address formats.
- Password (16 bytes): A 16-byte password length is typically enough, but ensure a secure password storage scheme, such as hashing with salt.
- Language (2 bytes): A 2-byte language code is a standard way to represent language and is usually sufficient.
- Avatar URL (200 bytes): A 200-byte avatar URL length allows for relatively long URLs for storing avatar links.
Storage Space (bytes) = Bytes per single user record x Number of users
Storage Space (bytes) = 322 bytes x 200,000,000 users = 64,400,000,000 bytes
Storage Space (GB) = 64,400,000,000 bytes / 1,073,741,824 ≈ 59.88 GBElasticsearch and Redis capacity estimation
For this classified platform, where user interest predominantly lies in the latest ads, a cost-effective approach involves Elasticsearch indexing only the content from the most recent three months. Concurrently, Redis will cache the top 20% of the most accessed content from the same period, employing a Least Recently Used (LRU) strategy for efficient data management. Additionally, Redis caches the top 10 pages of each category, as users often browse these top pages in their areas of interest. While caching other popular local pages is a consideration, it is currently beyond the scope of this discussion.
Daily Text Storage (Bytes)=Daily Posts×Words per Post×Bytes per Word
Given: Daily Posts = 10,000, Words per Post = 50, Bytes per Word = 5
So, Daily Text Storage=10,000×50×5=2,500,000 Bytes
Three-Month Storage=2,500,000×30×3=225,000,000 BytesElasticsearch Storage Requirement (3x Original Data Size): ~0.63 GB
Elasticsearch might require up to 3 times the original data size for indexing.
Max Index Storage (GB) = Three-Month Storage×3
Max Index Storage (GB) = 225,000,000×3 / 10243 ≈ 0.63 GBRedis Storage Requirement(assuming 108 categories):
Redis Cache Storage = Three-Month Storage × Percentage for Caching + (108 categories storage with 10 pages per category and 32 items per page)
Redis Cache Storage = 0.21GB × 0.20 + 0.00864GB = 0.05064GBHigh-Level Design
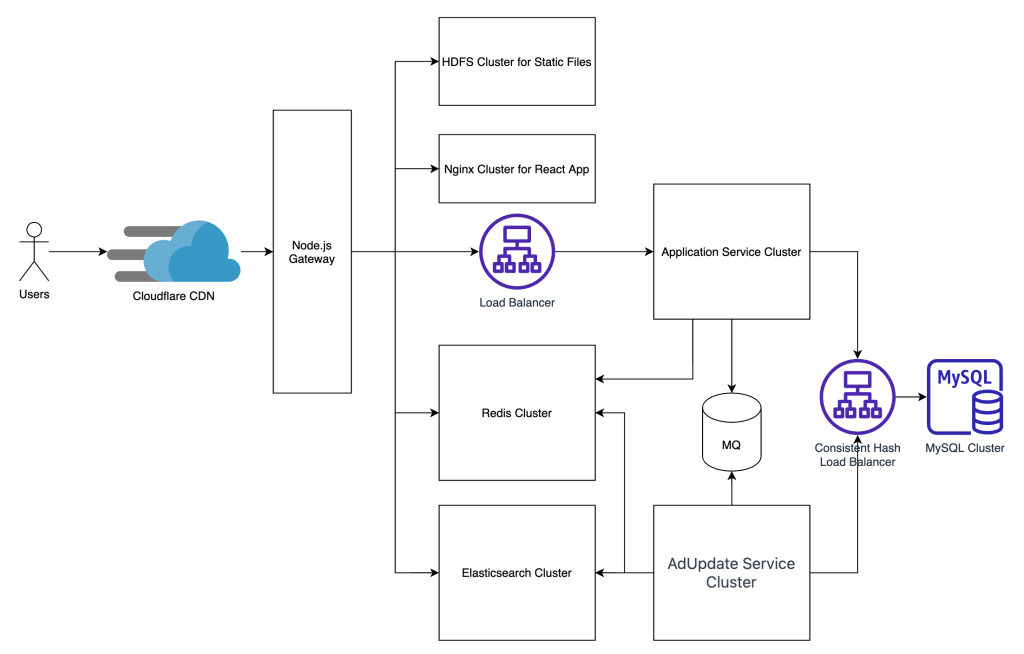
Search Requests:
- Incoming search requests are directed through the Node.js Gateway.
- The Gateway forwards requests to Elasticsearch for search operations.
- Elasticsearch processes the request and sends back results, optimizing search functionality.
Category and Product Page Retrieval:
- When category page requests arrive:
- The Node.js Gateway first checks the Redis cluster for cached results, utilizing a Redis sorted set to fulfill this requirement.
- Cached results are immediately served if available.
- In the absence of a cache, Node.js Gateway sends the request to the Application Service Cluster.
- Results from the Application Service Cluster are stored in Redis for future use.
React App is hosted on an Nginx Cluster
HDFS for Static Files Access:
- Static files, such as images and videos, are accessed through the HDFS for Static Files, which is managed by the Node.js Gateway.
- Centralized static file services enhance manageability and scalability.
Advertisement Updates:
- For add/update/delete requests regarding advertisements:
- The Application Service Cluster processes requests and sends relevant data to a message queue (MQ).
- A dedicated “Advertisement Update Service” monitors the MQ.
- This service handles advertisement changes, ensuring synchronization with Elasticsearch and Redis Cluster.
- Periodic or on-demand operation guarantees data consistency and updates.
Sharding
To evenly distribute Product Post storage and traffic across different shards, we’ll employ Consistent Hashing based on Product IDs. We’ve addressed high-frequency access to category pages and filtered searches with Redis and Elasticsearch.
For range queries, we query all MySQL shards, and then a Consistent Hash Load Balancer aggregates and filters Top N Items from all shards before returning the Top 10 Items to App Services or relevant calling services.
This design efficiently balances data and handles performance requirements, although it’s essential to monitor query complexity as data scales for optimal system performance.
Challenges
As evident from the previous discussions, meeting system requirements involves considering various scenarios from the outset. This entails procuring an adequate number of servers to accommodate business and user growth needs. Common challenges we’ll encounter include:
- Server Procurement and Deployment: How to dynamically scale server resources based on demand? There may be idle servers during off-peak hours, leading to resource wastage, yet they’re essential during peak periods.
- Daily Operations and Maintenance: Responsibilities encompass Gateway maintenance, cluster scaling strategies, regular backups, security patch management, monitoring, and performance adjustments.
- Security and Compliance: Ensuring regular credential updates to meet compliance requirements while managing data encryption, identity verification, access control (possibly through customized Redis API rate limiters), DDoS protection, IP restrictions, and more.
- Disaster Recovery
Although practices like automated operations and continuous integration/continuous delivery (CI/CD) can mitigate some of these challenges to a certain extent, it’s crucial to acknowledge the associated human and resource costs.
Questions
The challenges outlined earlier raise a fundamental question: How can we reduce costs, particularly in terms of operational expenses, while simultaneously enhancing system performance, and availability, ensuring data security and compliance, and meeting the demands of business growth and user expansion?
Solutions
Now, let’s delve into how AWS provides solutions to tackle these challenges.
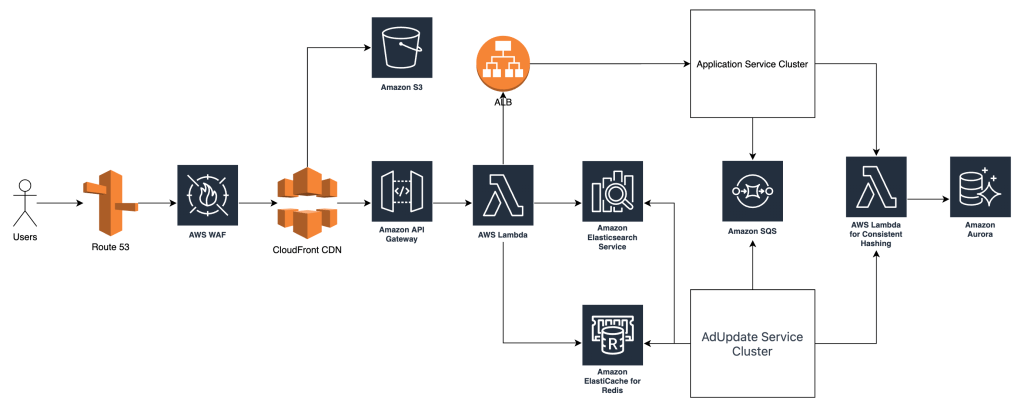
Design Details
The AWS cloud architecture has enabled us to tackle server procurement and deployment, operational costs, security, and disaster recovery more efficiently and effectively.
Route 53
By configuring Route 53, we meet our disaster recovery (DR) requirements, implementing a multi-location DR strategy. Additionally, Route 53 helps us deliver lower-latency services by intelligently routing traffic to geographically closer locations, enhancing user experience and providing more reliable services.
AWS WAF
WAF, integrated with CloudFront, effectively enhances the security of our services. It monitors traffic through configured rules and takes actions, such as IP blocking, upon detecting abnormal traffic patterns, effectively mitigating Distributed Denial of Service (DDoS) attacks. It can also be used for IP restrictions, like limiting access from specific geographic regions.
Cost Optimization
Although capacity estimation offers more controlled cost management and handles scenarios like traffic surges, using AWS cloud greatly simplifies server procurement and deployment. Additionally, the elastic scaling feature of cloud computing ensures more efficient resource utilization.
Static and Dynamic Segregation
S3 will be used to host front-end web app files and other static files like images, effectively reducing operational costs for HDFS and Nginx clusters. Additionally, as a highly available service, S3 supports cross-region data redundancy through Cross Region Replication (CRR) to optimize latency and aid disaster recovery under critical conditions.
Optimizing Application Service Clusters
API Gateway serves as the main gateway between front-end and back-end services, offering numerous out-of-the-box features such as rate limiting, security controls, and integration with serverless services like Lambda, greatly reducing our development and operational costs. As a regional service, each API Gateway can achieve 99.9% availability. Deploying it across multiple regions can further decrease latency and improve availability.
App Services instances deployed in an Auto Scaling group managed by ALB with memory-based scaling rules allow for cost-effective operations. Using Reserved Instances for regular traffic and On-Demand Instances for peak traffic efficiently reduces operational costs, improves resource utilization, and minimizes the waste of idle server resources seen in traditional on-premises models.
Replacing existing services with AWS Application Load Balancer, Amazon Elasticsearch Service, and Amazon ElasticCache for Redis significantly lowers operational costs while enhancing availability and security.
These services can be easily configured, scaled, and monitored by teams. Configuring deployments across multiple availability zones ensures failover capabilities. Elastic scaling further enhances efficient resource utilization.
AWS Aurora
AWS Aurora will replace MySQL, capitalizing on its compatibility with MySQL and performance advantages in high-load and large-scale data processing scenarios. AWS Aurora offers not just improved performance but also superior scalability.
Moreover, the use of AWS Aurora Global Database will further enhance system availability and reduce data access latency. It automatically replicates data across multiple regions, ensuring high data availability and durability. By providing data in regions closer to users, it effectively decreases access latency.
To manage loads more efficiently, we will incorporate Lambda services at the forefront of our architecture to implement consistent hashing. Lambda’s serverless and on-demand computing capabilities are ideal for handling irregular or burst workloads, thus further boosting the overall architecture’s flexibility and scalability.
Overall, combining AWS Aurora’s high-performance database solution with the flexibility of Lambda services, this architecture is designed to improve performance, enhance availability, and optimize user experience.
Migration
Considering the challenge of migrating hundreds of terabytes of data, AWS Snowball is an ideal choice. Snowball is designed for efficient and secure large-scale data transfers. Our plan involves initially using Snowball to migrate the bulk of the data, followed by utilizing AWS Database Migration Service (DMS) for synchronizing new data updates. Once all data synchronization is complete, we will carefully execute the database switchover to ensure a seamless business transition. While this discussion does not detail the migration of other services, it’s worth mentioning that tools provided by AWS, such as Service Discovery, play a crucial role in service orchestration and server performance assessment during the migration process.