A practical look at how repair windows, coordination overhead, and recovery behavior shape large-scale object storage systems.
Scale assumptions
Consider a distributed storage system at 10 billion objects.
Assume:
- 10B objects
- 5MB average size
- 50PB logical footprint
- 8+3 erasure coding configuration
- 200 nodes per region
- 2% annual node AFR
- 1GB per second sustained rebuild throughput
- 1KB metadata per object
This gives us:
- ~10TB metadata footprint
- ~500TB per node
- ~5.8 days to rebuild a single failed node
At 2% AFR across 200 nodes, that works out to roughly four node failures per year.
Durability models assume independence and full redundancy.
The moment rebuild begins, the system exits steady state.
From this point forward, availability depends on how quickly the system can restore redundancy.
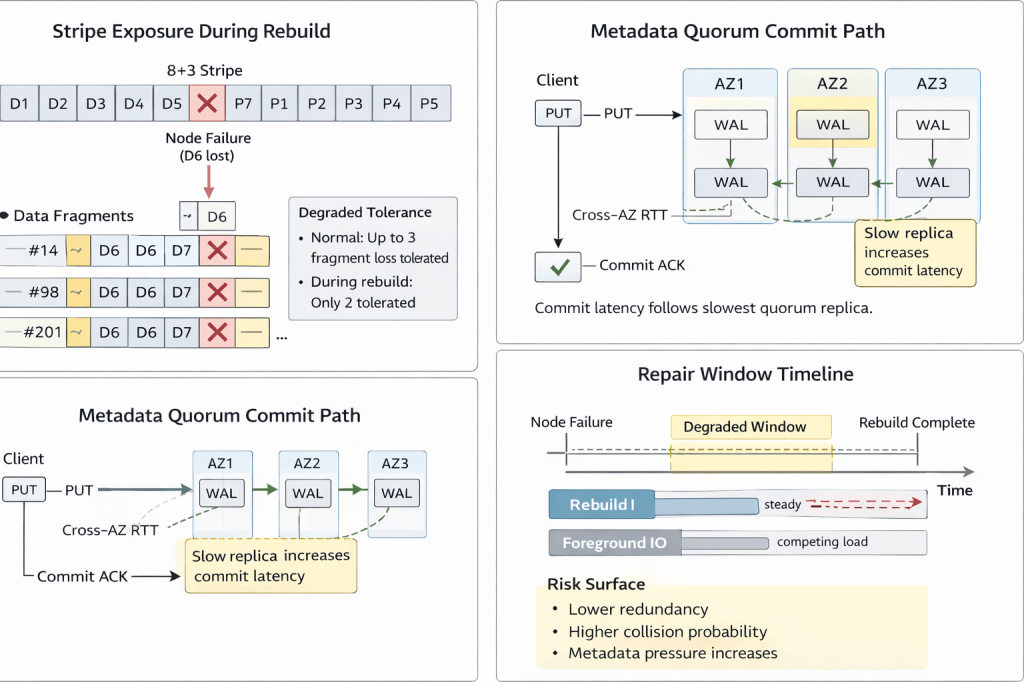
Stripe Exposure During Rebuild
Under 8+3 erasure coding, each stripe tolerates three fragment losses.
A single node failure reduces redundancy across every stripe containing its fragments.
500TB per node divided by 5MB objects implies on the order of 10^8 fragments per node. Each fragment participates in distributed EC stripes across failure domains.
During a five-day rebuild window, all of those stripes operate at reduced tolerance.
If stripe placement respects independent failure domains and maintains high entropy, second-failure collision probability remains bounded.
If placement skew exists, or topology coupling compresses fragment spread, stripe overlap raises the chance that a second failure hits stripes that are already degraded.
This is where you can no longer treat failures as isolated events.
The operational question is not theoretical durability.
It is whether rebuild throughput exceeds failure accumulation.
That is a capacity planning problem, not a math problem.
Repair Concurrency Is a Policy Decision
Rebuild bandwidth cannot be left purely opportunistic.
If rebuild competes freely with foreground traffic, degraded windows extend and tail latency drifts.
If rebuild fully dominates IO and network, write and quorum latency become unstable.
Production storage systems therefore require explicit policy:
- A minimum reserved rebuild bandwidth
- A maximum stripe reconstruction concurrency limit
- Dynamic throttling tied to tail latency and SLO
Without concurrency control, rebuild behavior becomes workload-dependent.
Durability math does not model this dimension.
SRE responsibility begins here.
Metadata Services as a Coordination Surface
At 10B objects, metadata services control namespace visibility and version state.
Ten terabytes of metadata is trivial to store, but coordinating it is not.
As shard count grows, hot prefixes create concentrated write pressure, and versioning or GC introduce additional write amplification. Listing operations fan out across partitions.
Under strong consistency semantics, each metadata commit requires quorum write across availability zones. Commit latency tracks the slowest replica in the quorum.
During rebuild, fragment re-registration and placement updates increase metadata write pressure.
If block redundancy drops, the data plane can still operate in a degraded state.
If metadata quorum stalls, namespace progress stops.
These are separate failure domains and need to be isolated operationally.
Policy must define:
Shard size ceilings
Hotspot detection and split thresholds
Backpressure triggers when quorum latency rises
Durability protects fragments. Metadata stability protects availability.
Strong Consistency Under Stress
Strong consistency is implemented through quorum write and cross-zone replication.
Each PUT typically requires:
- Multi-AZ persistence
- Metadata WAL replication
- Commit coordination
Under rebuild pressure:
- Replica lag increases
- Leader transitions become more frequent
- Write queues accumulate
Even small cross-AZ RTT increases become amplified under concurrency.
The system stays correct, but its behavior becomes less predictable.
Operational mitigation includes:
- Latency-aware admission control
- Commit batching under load
- Isolation between data plane rebuild IO and metadata IO
High availability depends on keeping coordination cost bounded, not just on redundancy.
Correlated Failures and Topology
Durability models assume failures are independent across disks, nodes, and racks.
Production reality includes:
- Batch firmware regressions
- Top-of-rack switch failures
- Shared power domain events
- Coordinated software rollouts
Correlated failures reduce effective redundancy much faster than MTTDL models suggest.
Mitigation requires topology-aware stripe placement and explicit failure-domain labeling.
Erasure coding improves efficiency, but it also increases cross-node coupling.
Replication reduces coupling but at a much higher cost.
In practice, each storage system decides where to place that trade-off.
Capacity Planning Beyond Raw Durability
Triple replication introduces roughly 200 percent storage overhead.
An 8+3 erasure coding layout has roughly 37.5 percent overhead.
Lower overhead cuts raw storage cost.
But it increases dependence on:
Network saturation margins
- Rebuild bandwidth reservation
- Scheduler fairness
- Stripe placement entropy
Capacity planning must therefore define:
- Minimum rebuild throughput per node
- Maximum acceptable degraded window
Failure arrival assumptions under correlated events
Durability is driven by probability. Availability during repair is driven by time.
What Separates Stable Systems From Fragile Ones
At 10B objects, system stability depends on:
Repair bandwidth reservation
Failure-domain isolation
Metadata quorum stability
Stripe placement uniformity
The system doesn’t need to avoid failure. It just needs to keep accepting writes and recovering in a predictable way during repair.
Durability is a probability target. Stability comes from operational policy.
